
我们常常在科研论文的数据分析部分或者某些科普文章引用的资料当中见到涉及P值的统计学报表以及相关的显著性判断。非专业读者看到这些关于P值和”显著性”的描述往往是一头雾水(如下表),大多略过,但实际上这些统计结果才是一篇论文中最准确直接的定性结论。了解了P值的含义和显著性的判定,可以帮助我们快速掌握科研论文中第一手研究数据的指向和意义。
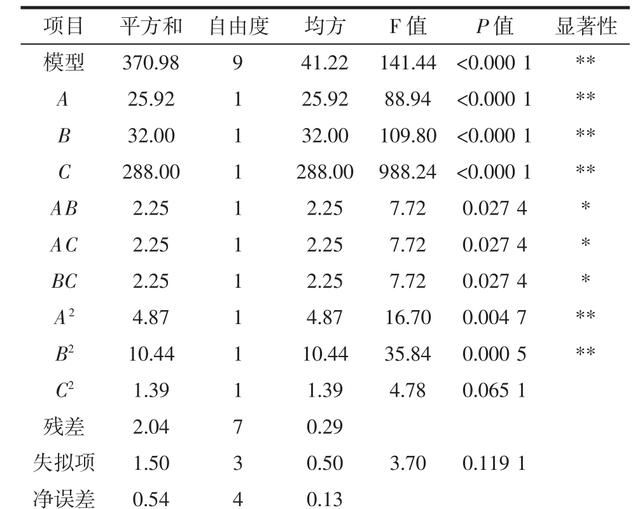
一个p值统计报表的例子
P值往往涉及统计结果显著性的判定,因此我们得从显著性的概念说起。本文将用通俗的文字来简介相关的统计学概念,并附上P值的计算方法。
统计显著性和置信度
任何理论(或认识)都没法保证其关于现实的推测是100%正确的,这归因于理论永远都只是对现实世界真相的大致概括和特征提取。理论只能无限趋近于真实,但无法达到真实。人类利用的仅仅是越来越接近真相的理论而已。
所以对于任何说法,都有一个可信度问题。而通过对于现实的重复测试,我们将能够了解某个说法究竟有多可信,不同的说法之间是存在着可信度的差异的。这就像是盲人摸象之后,每个盲人说出的有关大象外形的可信度是有差别的,而且只要让盲人们多摸几次,他们对大象长相的描述会越来越接近真实。
了解不同观点的可信度,是统计的目的之一。统计中所谓的”显著性”就是可信度的一种指标。
具有统计显著性的结果反映的是经过严格的测试得到的结果达到了一定可信度——专业术语叫“置信度”(又叫“置信水平”),它表明我们在多大程度上相信结论不会因随机因素而发生偏差。更具体地说,置信度是我们所持理论预测出来的结果在指定区间出现的可能性。
显著性跟置信度的内涵异曲同工,但它们的表述方法刚好相反,且在应用中描述方式略有差异:
· 对于置信度一般我们会说”……实验结果落在某个置信区间的可能性可以达到多高……”(这个可能性越大置信度就越高)
· 而对于显著性我们会说”……我们的理论假设被否定的可能性小于多少,我们的假设就可以被称为显著或者极显著……”(这个可能性越小显著性越高)
也就是说,置信度通常是正面描述(拒伪的),而且通常需要与一个置信区间关联起来。而显著性则是反面描述(拒真的),而且通常需要与一个预设的判断门槛值联系起来。
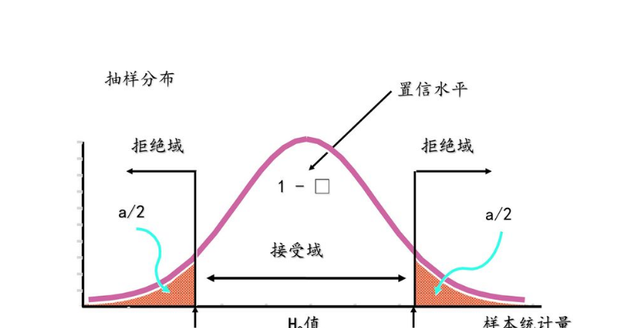
显著性与置信度(置信水平)的关系
P值和零假设
统计学使用P值来代表前面提到的”理论假设被否定的可能性“。科学研究往往会选取与理论提出的假设相对的情况作为”证伪对象”——即尝试证实”这种与我的观点相对的假设”不大可能发生,这种用来当”靶子”的假设在统计学中被称为“零假设”(又叫”原假设”,或者”虚无假设”,通常用H0表示,英文Null Hypothesis),通俗地说即:靶子被打倒,研究即成立。
所以,P值通常被用于在假设检验中描述某理论假设的有效性,通常理论的反面会被设为”零假设”。例如:我认为”读者阅读完本文的耗时大于10分钟”,其零假设便是”……读完本文的耗时小于10分钟”。因此我们只需要证明零假设发生几率相当小,那就可以说明我的说法是可信的。反之,只要证明我的说法的发生几率大到某个程度也可以证明我的理论。
但统计学上往往采用否定零假设的方式来断言某个说法的可靠性,而不是倒过来。因为概率论认为”小概率事件”在单次测试时几乎是不可能发生的。因此只要证明零假设是小概率事件就可以肯定对立假设了。这或许是统计分析往往采用否定零假设的方式来做置信度判定的原因。
于是我只需要真实地调查足够多的读者阅读本文的真实耗时,就可以算出P值。P值是一个概率,取值在0和1之间,即绝对可能和绝对不可能之间。因此,如果P值为5%,则置信度就是95%(两个加起来=1),这反映出我的说法跟现实的关联显著性较高,因此较为可信。
显然,如果零假设(”……耗时小于10分钟”)的发生可能性很低,即是个小概率事件,那么与之相反的对立假设(”……耗时大于10分钟”)的发生可能性就很高。小概率事件在单次测试当中几乎是不可能发生的,因此可以等同认为我的理论的单次断言是完全可信的(但不能说我的理论的全部断言都是可信的)。

零假设与对立假设就像在轮盘上猜滚珠落到黑格与红格的关系
P值是一个概率,是一个数,因此它可被用于衡量实验证据对结论的支持强度,并以下面的方式来做显著定性分析。确定统计显著性有三种主要方法:
· 如果进行的检验得到的P值小于预设的α水平,则这个测试具有统计学显著性。
· 如果置信区间不包含零假设的值,则检验结果具有统计显著性。例如置信区间
· 如果您的P值小于α,在置信区间上不存在零假设的值,因此具有统计显著性。(这是将前两点综合起来的推论)
注意:α值是人为预设的一个标准。根据经验惯例,α值通常取0.05作为显著性的判定标准,取0.001作为极显著的判定标准,也就是说。
· 较小的P值(通常≤0.05)表示实验结果是零假设不成立的有力证据,因此零假设可以比较可信地推翻。
· 较大的P值(> 0.05)表示反对零假设的证据不充分,意味着零假设成立的几率偏大。
· 极接近临界值(0.05)的P值被认为是边际性的(这有点信不信由你的味道)。
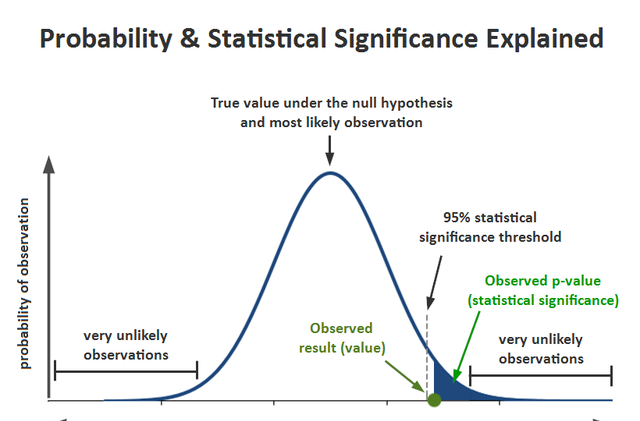
P-值的图示解释
上图:概率及统计显著性示意。纵轴是观察的概率,横轴是结果可能的取值。
- Very unlikely observatiOns= 非常不可能的观察结果
- Observed Result(value) = 观察结果(值)
- 95% statistical significance threshold = 95%统计显著性门槛值
- Observed p-value (statistic significance) = 观察到的p值(统计学显著性)
用一个栗子小结一下
例如,我刚在”饿了吗”上点了一份餐,饿了吗估算的送达时间是30分钟,但我坚持认为通常30分钟内都送不到。所以我可以进行一次假设检验,因为我认为”送达时间在30分钟以内”的零假设是不正确的,因此我的对立假设是”送达时间大于30分钟”(也就是说会迟到,要知道送餐迟到饿了吗就要赔优惠券,哈哈)。
为了证实我的观点,我每天都点这同一家餐馆,并实测每次送达所花的时间。在获得了大量的样本数据之后,我计算了样本的P值,假设P值是0.001(远小于0.05),这意味着,我关于”送餐会迟到的判断会是错误的”的可能性大概是0.001,或者说我判断错误的可能性远小于0.05这个”统计学显著性的经验门槛值”。因此,我基本上可以相信饿了吗自动估算的时间是错的,这样一来饿了吗每次都应该给我赔偿优惠券。
但现实中这只是我的痴心妄想,基本上没可能,因为饿了吗公司的开发人员可没有那么傻。他们一定会根据每次送餐的送达时间的统计情况,不断刷新它们的估算公式,以确保他们估算结果的P值<0.05,甚至更低。饿了吗APP搜集的大数据会确保在绝大多数时间,送餐人员的的递送时间都不会超时(当然他们的算法可能会更复杂,统计学结论可能只是其中的一部分)。
饿了吗的超时赔付政策背后是有统计学显著性支持的
如何对待统计学显著性对某项研究的意义?
置信度会因为一个重要的原因而降低——抽样误差,它是数据扭曲的常见原因。显然,如果你研究基于的是有缺陷的数据,结论肯定不会正确。
例如,你希望调查大众最喜欢的食物。但是您跑到麦当劳去调查,那么结果可能是最喜欢吃牛肉汉堡;但如你跑到素餐厅去调查,结果就大不相同了。这就是一个被夸大了的抽样误差问题。但所有的抽样都会存在抽样误差,只是误差大小区别而已。因此,统计上的显著性并不一定能保证客观上是正确的。这就是我们经常发现一些貌似数据很有说服力的论文的结论被其他同类研究推翻的原因之一。
在科研领域,统计显著性往往并不能完全断言研究人员的假设就是100%正确的,但往往能够告诉研究人员他的假设是有一定可信的事实基础的,值得进一步研究。
如何计算P值?
这个部分是写给有兴趣了解在统计学上P值是如何计算的读者的。如果您只是想粗浅地了解下P值和统计学显著性的概念,那么后面的内容就可以略看或者不看了。
计算并确定统计显著性有点复杂,往往实用中会用一些软件工具来计算,例如IBM的SPSS或者开源的Jamovi,这两者都是统计学分析工具。此外,网上还有一些在线计算器,主要有Z测试计算器和T测试计算器之类,专用于做显著性相关统计学评分的计算。
我在这里会介绍如何手工计算统计显著性 ,这里是采用t分数来获取P值:
步骤1:设定零假设和对立假设
先指出哪个是零假设(H0)。在科研中,零假设通常会被设定为实验措施无效,这意味着实验失败,也就是研究人员希望通过实验否定的那个假设。
零假设确定之后,对立假设(Ha)也就确定了——对立假设与零假设在逻辑上互否。在科研中,对立假设通常是说科研需要证实的那个措施,这意味着实验成功或者具有进一步研究意义。
例如,假设我们研究某种药物对病人的有效性。我们的零假设将是:”这种药物对病患完全没有影响。” (既没有正向的影响,也没有负向的影响)
但通常测试药物是否有效是通过”实验组”样本与”对照组”样本的差别来确定的。对照组通常会给予”安慰剂”,这相当于没有服药(但是对照组的病人并不知道自己是否服用了有效的药物)。
如果实验组的结果与对照组没有差异,则表示药物无效。所以零假设可以转设为 “实验组和对照组没有差异”。因此,只要我们通过统计分析否定这个零假设,即可得出支持药物有效性的结论。
对照组
步骤2:选取α值
我们需要设定一个显著性门槛的级别,即前述α值,确切的说其含义是:某假设被认为可信时零假设可能成立的概率(这可能有点绕)。
通常α值选取为0.05(即5%)作为显著性的门槛,但不同实验敏感度要求不同。在某些领域的研究当中,可以提高显著性的门槛,诸如药物测试或精密仪器制造等等,对于这些领域,可能选取0.01更为合适。
由于置信度= 1-α(%),因此如果α值为0.05,那么达到此门槛的测试统计结果置信度就为95%。

阿尔法值和双侧或单侧测试的示意
步骤3:单侧(one-tail)或双侧(two-tail)测试
(在某些资料上也被称为one-side或two-side测试)
在获取P值之前需要确定采用单侧测试还是双侧测试更恰当。
· 单侧测试在一个方向上检查两组对象数据之间的关系,例如药物使病人病情改善;
· 而双侧测试从正反两个方向上进行测试,例如药物使病人病情改善或者恶化。
如果您不确定结果会朝哪个方向发展,那么采用双侧测试也是OK的。
单侧或者双侧的选项在最后我们在t值表上查询p值的时候需要用到。
步骤4:确定样本数
接下来,确定样本数满足统计需要。
实际上这是一个先决条件,必须在实验测试之前或者在实验后处理数据之前确定我们至少需要获得多少样本才能确保置信度或者显著性能够到达期望的显著性标准。因为在实操当中往往有些样本因为无效而被排除,这很可能导致样本数达不到要求,因此在完成实验之后进行数据处理的时候也需要重新核实样本数满足下限要求。
确定样本数下限,我们需要进行统计功效分析。如果样本数太少会使置信度(或者显著性)不足,造成假阴性的结论,而样本数太多则会增加统计的实施成本,费了力却讨不到多少好。一般来说,统计功效越高假阴性的可能性就越低。
功效分析包括四个主要部分:
· 效应量,它告诉我们结果在被统计群体中的影响力大小,如果效应不足,即便显著性达标也不能说明结果的实用性;
· 样本数量,它告诉我们样本中有多少个观测值;
· 显著性水平,即α值;
· 统计功效,即我们接受对立假设的概率;
许多实验均采用80%的典型功效(或1-β,β称为假阴性率),进行分析。这个值也只是人为确定的经验值,可以根据需要更改。进行功效分析可让我们知道在指定的置信区间上达到统计显著性所需的样本数量,即通过指定β值和α值求出必要的样本数。
由于统计功效计算相对复杂,一般会利用工具软件进行计算。

α值和β值实际上对应两类统计错误
上图:两类统计错误。
- 零假设为真,但被拒绝,此为第一类错误,或者α错误;
- 零假设为假,但未被拒绝,此为第二类错误,或者β错误;
足够的样本数就是为了尽量规避β错误。
步骤5:计算标准差
标准差 s (有时也写成 σ,全称是”标准偏差”)可以让我们知道数据的分散程度(越大越分散)。这是统计学上最常用的概念,其计算也不复杂。
样本标准差公式为:

在这个方程式中
· s 是标准偏差
· ∑ 是求和的意思
· xi 是每个单独的数据
· 带上划线x 是每组数据的平均值
· n 是总样本数量(这里用n-1而不是n是为了降低系统误差,在描述性统计中会采用n而非n-1作为标准差计算;当n趋近无穷大时,这两种计算方法的结果会趋近)
步骤6:计算标准误差
(注意标准偏差和标准误差的差别)
在上一步我们已经求得了两个标准差,接下来我们需要求两组数据的标准误差。计算公式如下:

公式中:
· SE 是两组样本之间差别的标准误差
· σ1 是第一组的标准差
· n1 是第一组的样本数量
· σ2 是第二组的标准差
· n2 是第二组的样本数量
步骤7:求t分数
t分数是用于度量估计值(或称为一组待验数据)与已知参考值(或称为另一组参考数据)之间的平均偏离程度相对于其标准误差的比例,这个程度可以告诉我们两组数据是否显著不同。计算t分数的公式是

其中:
· t0是计算得到的分数
· 上划线x1-x2两组数据平均值之差
· SE是两组数据的标准误差
步骤8:确定自由度
自由度(dF)即每组变量可以有多少个值可以选择用于分析。若两组样本进行比较,那么应该用两组样本数相加并减去二(实际上应该严格描述为各组样本数减一再相加)。
例如:如果有两组数据一组有10个样本,另一组有20个样本,那么第一组的自由度是9,第二组的自由度是19,两组一共有28个自由度。
步骤9:使用T表查找P值
因为小样本量的随机测试均值的分布不是正态分布,而是T分布。因为T分布的计算函数比较复杂,所以一般通过查t值表来获得P值。
下面是一个t值表:
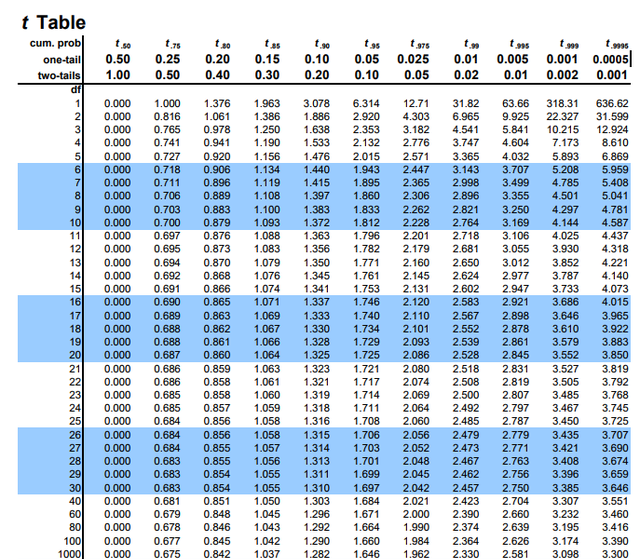
假设我们的实验采用单侧测试,两组数据总共有28个自由度,计算出来的t值是3.5左右。
1. 我们首先在最左侧df(自由度)一列查找,找到自由度为28那一行;
2. 然后再此行搜索我们的t值,我们可以发现大概是在左侧两列的数值(3.408-3.674)之间;
3. 在这两列顶部one-tail(单侧)一行查看对应的p值为0.001到0.0005之间。
根据这个p值我们即可判断,我们测试的两组数据的差异极其显著。
总结
通过本文了解了P值和统计学显著性的涵义之后,读者可以在今后阅读科研论文时尝试理解其中涉及统计学显著性的数据的内容。
而对于某些有数据分析能力但对统计学假设测试分析尚不太熟悉的读者(包括某些统计应用程序的开发者),希望这部分读者通过本文了解了P值的算法之后,可以大概理解求取P值的统计学思路,以便在自己的工作中逐步尝试理解更多的统计学细节(当然具体计算还是推荐采用计算工具哈)。
本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com
