
不过还好调整了过来,还是会继续坚持周更的。毕竟学习是一件永无止境的事,用输出倒逼自己输入,才能有所沉淀和成长,欢迎大家监督和共勉~
这篇文章是介绍幂等的。幂等在分布式和高并发场景下是必须要考虑的一件事。如果不做幂等,轻则产生脏数据,重则产生业务异常,造成资产损失。
什么是幂等?
幂等原本是一个数学上的概念,表达的是N次变换与1次变换的结果相同。即公式:f(x)=f(f(x)) 成立。
用在编程领域,表达的是对于同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。
一般来说,读操作天然都是幂等的(除非你的读操作有副作用),而写操作是不幂等的。但是有些业务场景我们需要做到写操作幂等,所以需要做一些额外的工作。
比如提交订单请求,有时候可能是同样一个订单,如果不做幂等,重复处理,就有可能会造成用户或者公司的资产损失。
幂等在并发量较高的项目中是一个经常会遇到的问题。主要有以下两种场景会遇到幂等问题:
- 请求重复提交/消息重复提交
- 失败重试
下面分别谈谈这两种场景的具体的解决方案。
重复提交下的幂等
重复提交,很大的概率是前端设计不合理或者客户端网络问题,导致用户连续提交多次相同的内容。对于这种场景,可以在前端改善用户交互,在后端也可以简单地判重和拒绝。这种场景比较适合在外围做幂等,直接把请求拒绝或者pass,不用把请求放到业务内部。应该做成一种较为通用的能力。
从前端防止用户重复提交
前端交互很重要,因为用户其实并不管幂等不幂等,有时候客户端可能由于手机卡死或者网速较慢,提交了迟迟得不到反馈,可能会疯狂点击提交按钮,导致产生大量的重复请求。
常用的解决方案有:跳转到其它页面,如订单提交后跳转到提交成功页面;点击提交按钮后清空内容,适用于评论、回复等业务场景。还有按钮置灰等设计。
我的个人网站上可以找到类似的例子,比如评论组件,评论提交后,会将提交按钮置灰60秒。


使用缓存实现重复提交幂等
要解决重复提交幂等的方案很简单,用缓存来做就行了。我们把请求参数(JSON序列化为字符串)或者请求参数中的业务唯一ID作为key,存进缓存里。后续如果有其它一样的请求过来,就先去缓存里面查,如果存在,就直接跳过或者返回。
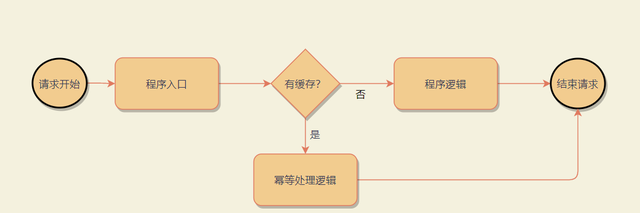
这里有一个问题,如果写操作有返回值怎么办?比如我们经常会有这样的设计:数据库的主键是自增的,往数据库插入一条新的记录,持久层会返回我们新插入记录的ID,而我们后续的程序会需要用到这个ID。
如果要实现幂等,肯定是第一时间写进缓存key,DB生成ID返回后,再把它插入到缓存的value里。中间有个时间差,如果这个时间差内,其它的请求过来了怎么办?
对于这个问题,如果业务上允许后续的请求直接报错,那可以直接抛异常出去,比如提示用户:订单提交失败。但这样通常对用户来说并不友好。另一种解决方案是,提前生成ID,ID通过参数传进去,而不是用DB生成,这样写操作就不会存在这个问题了。而生成ID的是一个很快的读操作,对这个读操作也可以做一个幂等,保证短时间内,同样的请求参数,只生成同一个ID。
单机幂等还是分布式幂等,取决于我们用的是单机缓存还是分布式缓存。大多数时候,如果我们的业务是分布式的系统,更建议用redis等分布式缓存来实现分布式幂等。
我们也可以实现一个很方便的幂等注解。其实原理很简单,自定义一个注解,用spring AOP加上缓存来实现幂等。也有现成的轮子:idempotent-spring-boot-starter,可以参考一下。
失败重试下的幂等
失败重试幂等其实也是会重复提交,但处理方式不同,不应该简单地拒绝掉,可能会只是某些步骤做幂等,但是请求会继续往后走,进入业务流程内部。比如提交订单,提交后会进行很多写操作,如优惠券状态修改、库存扣减、创建物流信息等。如果中途因为某种意外原因失败(比如网络原因等),可以进行重试。
而失败重试的时候,如果不做幂等,会产生问题。比如库存扣减操作,如果因为超时原因重试,可能会扣减两次库存,造成数据错误。但如果直接拒绝后面的请求也不妥,可能第一次请求确实是因为网络原因,处理失败了,第二次重试说不定就成功了,所以还是应该让后续的请求进来,采取其它措施来保证幂等。
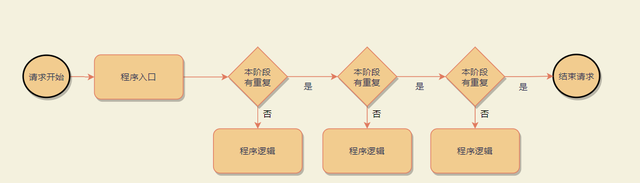
对于失败重试场景下的幂等,下面也有一些解决方案。
唯一ID/token
为每一次操作都生成一个单独的唯一ID或者token(以下简称token)。一个token在操作的每一个阶段只有一次执行权,一旦执行成功则保存执行结果。对重复的请求,返回同一个结果。
在订单提交的场景,订单ID就可以作为一个token。每一个环节执行时都先检测一下该订单ID是否已经执行过这一步骤,对未执行的请求,执行操作并缓存结果,而对已经执行过的ID,则直接返回之前的执行结果,不做任何操作。
在写操作之前,还可以用这个token进行上锁,保证同一个token只进行一次写操作。
开源轮子可以参考:redis-auto-idempotent-spring-boot-starter
乐观锁
可以乐观锁的思想,利用版本号去做幂等,这个比较适用于更新操作。
每条数据都有一个版本号,数据更新的时候,传入获取到的版本号,且版本号+1。在实际进行写操作的时候,会去比较请求参数里面的版本号,每个version只有一次执行成功的机会,一旦失败必须重新获取。
UPDATE demoSET count = count + 1, version = version + 1WHERE id = 123 and version = 5;防重表
利用数据库主键或者唯一索引的特性,保证相同的数据只会被写入一次。
比如在评论场景,我们可以把文章ID + 用户ID + 评论内容作为一个唯一键,那对于同一个文章,同一个用户,就不能提交多条相同的评论了。
但是个人不推荐这种方式。因为性能较差,而且DB的主键冲突,一般归于系统异常,如果用它来做去重,异常类型和日志不太好定义。
任务幂等
任务幂等,指的是对于同一段数据,触发一次任务和多次任务是相同的结果。
任务基本上都会涉及到写操作。如果同一段数据,被多次任务触发,进行了多次写操作,可能会造成脏数据。
其实也很好解决,我们在抽象任务模型的时候,给任务设计好不同的状态就行了。比如任务初始化、启动后、成功、失败、取消等都有不同的状态。后续的任务触发请求,如果监测到这段数据的状态已经做了修改,就根据这个任务的状态和用户定义
的策略,来决定是跳过还是重新执行。
可以参考Spring Batch的设计,Spring Batch抽象了Job这个概念,提供了BatchStatus枚举来作为任务的状态:
public enum BatchStatus {STARTING, STARTED, STOPPING, STOPPED, FAILED, COMPLETED, ABANDONED }相应的,比Job粒度更小的Step也有自己的状态。同时Spring Batch可以允许用户自定义地配置skip策略和失败处理策略。
消息幂等
消息幂等也是经常要考虑的问题。还是之前电商系统中订单提交的例子,比如库存扣减这种操作,为了保证吞吐量,可能会使用消息来实现。
消息幂等的概念可以总结如下:
如果消息重试多次,消费者端对该重复消息消费多次与消费一次的结果是相同的,并且多次消费没有对系统产生副作用,那么我们就称这个过程是消息幂等的。
对于消息来说,发送端可能产生重复消息,消费端也可能会重复消费同一条消息(大多数都是因为网络问题)。如果靠消息中间件去实现幂等,是一件比较困难的事情,增加幂等的处理会导致消息中间件的吞吐量下降。所以绝大多数消息消息中间件本身不处理幂等问题,而是交给了业务端自己去处理。
而不论是发送端重复还是消费端重复,我们只需要保证消费端幂等就可以了,不需要在发送端做什么事情。而消费端做幂等,其实本质上也是上面提到的“重复提交下的幂等”,比较适合在消费端的入口处就做幂等处理。
求个支持
我是Yasin,一个坚持技术原创的博主,我的微信公众号是:编了个程
都看到这儿了,如果觉得我的文章写的还行,不妨支持一下。
还有学习资源、和一线互联网公司内推哦
本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com